
Análise exploratória do ENEM 2016
- Jonas Euler
- 16 de mai. de 2021
- 5 min de leitura

Atualizado: 17 de mai. de 2021
Introdução
Olá! Hoje eu irei fazer uma análise de dados do ENEM 2016. Vale lembrar que o notebook e o dataset utilizado está no meu repositório do GitHub: https://github.com/Visheuleer/analise-enem2016
Objetivos da análise
Meus objetivos são:
Analisar algumas questões sociais que foram feitas aos candidatos
A renda familiar realmente influencia nas notas dos alunos?
Quais grupos sociais tem as melhores notas?
A etnia influencia nas notas?
Ter ou não ter internet influencia na nota?
Inicio da análise
A primeira coisa que eu fiz foi diminuir o dataset, pois ele tinha 13.730 linhas e 167 colunas. Para nossos objetivos apenas algumas dessas colunas seriam necessárias, então selecionei as seguintes colunas:
SG_UF_RESIDENCIA (Estado onde o aluno mora);
NU_IDADE (Idade);
TP_SEXO (sexo);
TP_COR_RACA (Etnia);
NU_NOTA_MAT (Nota em matemática);
NU_NOTA_CH (Nota em ciências humanas);
Q025 (Candidato possui internet?);
Q006 (Renda familiar mensal);
Q002 (Escolaridade da mãe do aluno)
Q050 (Candidato reprovou ou abandonou a escola durante o ensino médio?)

Utilizando o:
já foi possível de observar que existem dados faltantes, que são representados por 'NaN'. Esses dados faltantes estão presentes apenas nas notas das provas, e acredito que representam os alunos que fizeram a inscrição para o exame e não compareceram para realizar o vestibular.
Facilitando o entendimento das linhas
Alguns dados possuem valores que sem o dicionário do INEP sobre os dados não daria pra saber o que representam. Então, para facilitar o entendimento e a visualização dos gráficos futuros, eu decidi renomear esses dados. Segue o código e os valores que tiveram seus nomes alterados:
df_enem['TP_COR_RACA'] = df_enem['TP_COR_RACA'].map({0:'NA', 6:'NA', 1:'Branca', 2:'Preta', 3:'Parda', 4:'Amarela', 5:'Indígena'})
df_enem['Q002'] = df_enem['Q002'].map({'A':'Nunca estudou', 'B':'Não completou EF', 'C':'Não completou EF', 'D':'Não completou EM', 'F': 'Graduada', 'G':'Pós-graduada', 'H': 'Não sabe'})
df_enem['Q025'] = df_enem['Q025'].map({'A':'Não', 'B':'Sim'})
df_enem['Q050'] = df_enem['Q050'].map({'A':'Não abandonou nem foi reprovado', 'B':'Não abandonou e foi reprovado', 'C':'Abandonou e não foi reprovado', 'D':'Abandonou e foi reprovado'})Lembrando que você não precisa entender os códigos para acompanhar a análise, apenas coloco eles aqui para ilustrar o que eu fiz.
Primeiros gráficos e análises sobre as questões
Utilizando o:
montei alguns gráficos que me proporcionaram alguns pontos interessantes.

Percebi uma disparidade muito grande do número de candidatos pardos, brancos e pretos com amarelos e indígenas. Decidi pesquisar um pouco mais e descobri que segundo o IBGE apenas 1,1% da população brasileira se declara como indígena ou amarela. Então minha hipótese é que isso se reflita no número de alunos dessas etnias que fizeram a prova.

Esse gráfico mostra alguns pontos interessantes: Existem mais pessoas sem nenhuma renda familiar do que pessoas com renda familiar maior do que 10.560.
Outro ponto para observar é que a maioria dos alunos tem renda familiar de até 1.320.
O que me causou uma dúvida, será que existe uma relação entre etnia e renda familiar? Com esse pensamento na cabeça, resolvi cruzar esses dados.

Esse gráfico é bem revelador. Existem mais brancos nas rendas de até 10.560 e mais de 10.560 do que qualquer outra etnia.
Os pardos são os que mais não possuem nenhuma renda.
Os indígenas e amarelos são as etnias com mais baixa renda.
Decidi pesquisar um pouco mais sobre essa possível diferença de renda entre pessoas brancas e outras etnias. Encontrei apenas a pesquisa do IBGE que diz que em 2018, 32,8% da população negra no Brasil estava abaixo da linha da pobreza, enquanto 15,4% das pessoas brancas se encontravam na mesma situação.


Nesse gráfico percebi dois pontos relevantes: A maioria das mães não completaram o ensino fundamental. O número de mães pós-graduadas e que nunca estudaram é praticamente o mesmo.
Analisando as idades e notas
Decidi utilizar o:
para observar alguns valores como média nas provas, idade mais nova/velha e etc.

Pontos interessantes que observei: a média da prova de ciências humanas é maior do que a de matemática, porém, a maior nota de matemática é superior a da maior em ciências humanas.
A pessoa mais velha a realizar o exame tinha 67 anos (fica a dica, nunca é tarde para aprender). Já a mais nova tinha 13, o que é no mínimo curioso. Provavelmente algum superdotado ou erro de digitação. Depois disso, decidi plotar gráficos para uma melhor visualização dessas informações.
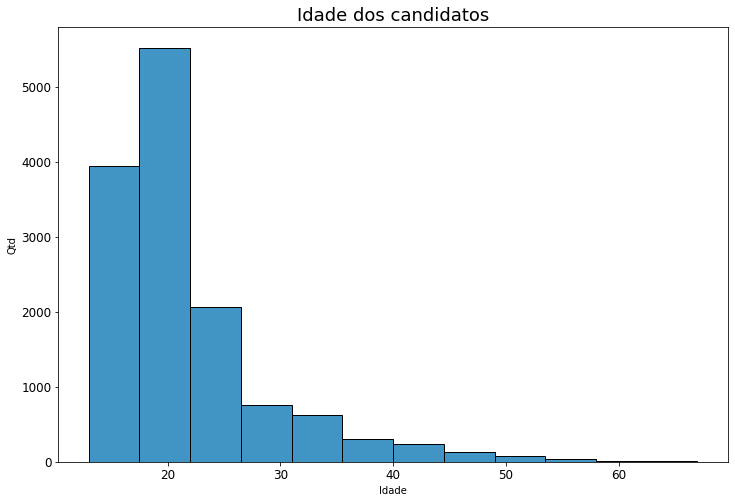

Interessante observar que ambas as provas obtiveram alunos que zeraram, porém o número de provas zeradas em matemática é ligeiramente superior a ciências humanas.

Observei dois pontos interessantes e que me fizeram pensar em uma hipótese. As maiores notas estão mais ou menos entre os 17 e os 22 anos.
O outro ponto é que observando bem, parece existir um padrão nesse gráfico. Perceba que a medida que avançamos para direita no gráfico, os pontos vão cada vez abaixando mais.
Mas o que isso significa? Significa que se minha hipótese estiver certa, existe uma correlação entre idade e nota. Essa correlação seria que quanto mais idade, menor a nota.
Com essa hipótese na mente, decidi usar o:
que vai traçar uma linha e mostrar se existe mesmo essa correlação.

Perceba que a linha está inclinada da esquerda para direita, o que confirma minha hipótese de que, quando a idade aumenta, as notas diminuem.
AVISO IMPORTANTE Apesar dos números estarem correlacionados, isso NÃO quer dizer que existe causalidade. Ou seja, não podemos afirmar que porque uma pessoa fica mais velha, a nota dela cai.

Exemplo: Esse gráfico tirado do site: http://www.tylervigen.com/spurious-correlations mostra a correlação entre o número de pessoas que se afogaram na piscina e o número de filmes em que o Nicolas Cage aparece.
O gráfico mostra que os números estão correlacionados, mas sabemos que não tem efeito de causalidade, pois, não é porque uma pessoa se afoga que o Nicolas Cage participa de um filme.
Aqui fica uma indicação da explicação dos conceitos: https://www.youtube.com/watch?v=l4Byu2Dym2A
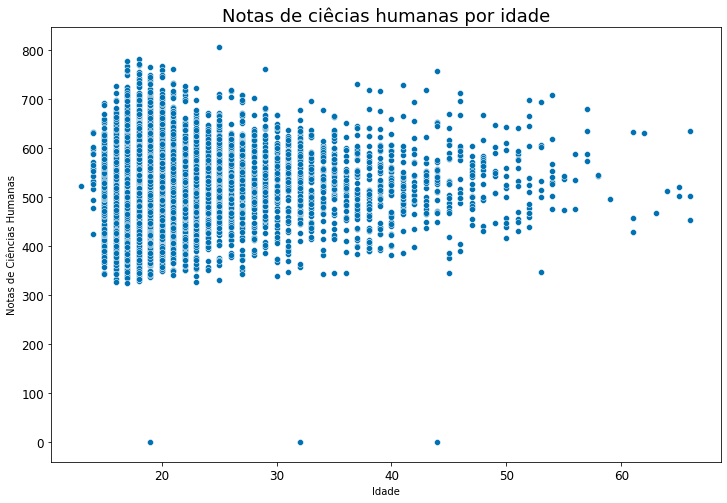

Observamos a mesma correlação na prova de ciências humanas também.
Cruzando notas com os dados sociais dos alunos
Para finalizar a análise decidi comparar as notas com os dados sociais dos candidatos.

Observei que existe uma claríssima relação entre o aumento da renda e o aumento da nota em matemática.

Mais uma vez, existe uma clara relação entre o aumento da renda e o aumento da nota em ciências humanas.

Dois pontos interessantes aqui: Os amarelos tiveram notas de matemática maiores do que pardos e pretos, já os indígenas tiveram notas ligeiramente inferiores do que os pretos e pardos.
Os brancos tem as melhores notas, o que pode estar associado com a relação entre o aumento da renda e o aumento da nota que vimos anteriormente, pois, as maiores rendas familiares são de pessoas brancas.

Observando o gráfico foi possível ver que quem possui internet tem notas superiores.
Conclusões
A renda familiar realmente influencia nas notas dos alunos? Quais grupos sociais tem as melhores notas? A etnia influencia nas notas? Ter ou não ter internet influencia na nota?
Os dados indicam uma tendência de aumento das notas com o aumento de renda.
Os brancos e as pessoas com renda maior do que 10.560 mostram as melhores notas do exame.
Existe uma forte indicação de que a etnia influencia nas notas, sendo amarelos e brancos com as melhores notas.
Os dados mostram que ter internet influencia no aumento das notas.
Essa foi minha análise sobre o Enem 2016. Fica aqui minha deixa para que você possa refletir sobre desigualdade social, acesso a educação de qualidade e meritocracia. Se você tiver alguma observação, elogio ou crítica, por favor me avise. Adeus e até a próxima!

Comentários